Blog Article
A Story About Salaries At Mindera — Part 3

Mindera - Global Software Engineering Company
2021 Sep 17 - 1min. Read
Share
Copy Page Url

A Story About Salaries At Mindera — Part 3.
Every once in a while, we like to share news about the Salaries in Mindera.
Four years ago, Sofia Reis wrote a story about salaries at Mindera where she explains how we did reviews back when we were around 200 minders: we had a small group of people that got together every 3–4 months to review salaries based on 2 questions:
- If we were hiring this person right now, how much would we offer?
- Can our business afford it?
Two years ago, on [a story about salaries at Mindera | Part 2](https://mindera.com/blog/mindera-or-a-story-about-salaries-at-mindera), Pedro Vicente shared some experiments we were doing:
- Open a Salary Transparency group where everyone is invited to share their salary details
- Try a Salary Self Proposal Model where each person is invited to create their own salary increase proposal
Yes, your guess is correct! Two years went by and our process keeps growing with us. Ready for one more twist?
So, we were doing self-proposals on our internal platform and also collecting information from everyone, to have a comparable view of all colleagues’ perspectives. Following that process, a small group of people got together to make sense of this information in order to review everyone’s salaries.
As we grew, the process of collecting comparable information from all colleagues began to be overwhelming: how are we going to do this in a universe of 800 people?
We felt it was time to evolve this review process, as we still felt that collecting this info directly from the people that work with us every day seemed like the best option, especially because this helps us to reduce the bias (almost) in the process.
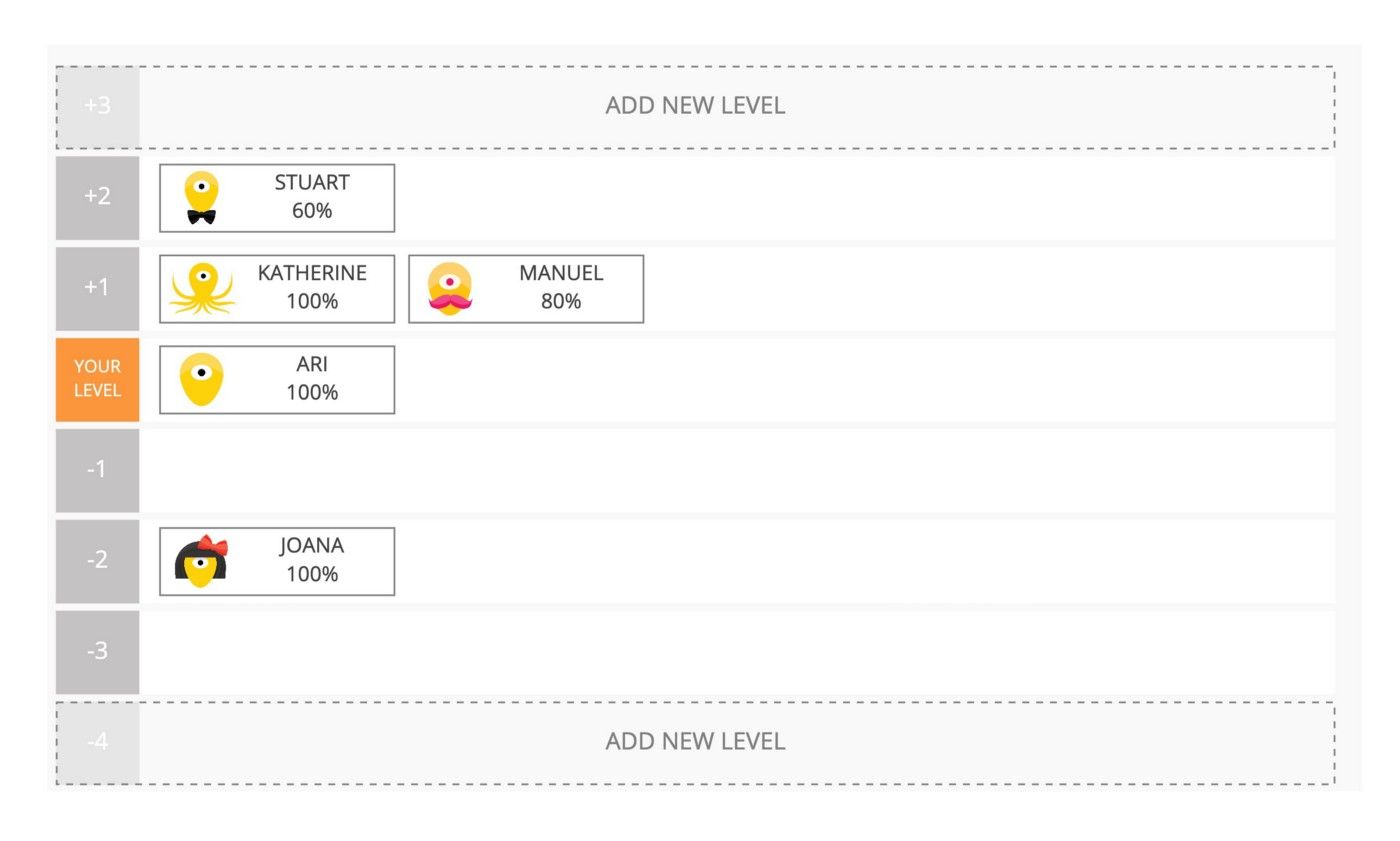
As referred to in our second article, some of our teams were doing an experimentation with a comparison model where each person builds a stack with several levels and includes their peers in different levels, according to the value they bring to their individual relationship, to the team and to Mindera.
For each person included in the exercise, the one building the stack has to define the confidence level of the comparisons from a scale of 1–100%. If you work closely with a colleague for a longer period of time, you’d go for a confidence level of 80–100%, if you’re comparing a new colleague that joined the team a couple months ago, maybe you’d go for something like 25–50%. Then these stacks would be the driver for the review process, the confidence level is visible to the review group.
Make no mistakes, this is a challenging exercise! Especially the first time you do it… you start wondering if placing a person above you is rude or will block their salary progression, you will question your knowledge to do the exercise even though you work with your colleagues every day.
After a while, you stop second guessing yourself and the exercise becomes what it really is: a picture of how you see the value brought by every colleague, when compared to others — it aims to capture that moment in time, instead of looking back to the last 12 months. Maybe in a couple of months things will change, and you’ll adjust your stack — please note the salary cycle process happens every 4 months.
Because we believed that this model was a good way to collect comparisons about a large group of people divided in several teams and locations, we decided to build a new tool on our internal platform that would help everyone provide comparisons and comments about the people participating in each Salary Review Cycle. We call it People Comparisons.
With this new tool: People Comparisons, we were looking for an easier process, and also accountability in the comparison each person creates. One can create several stacks, depending on how one prefers to structure the information. The main goal is that everyone participates, gives input and the result seems to be perceived as fairer (probably due to the participation of everyone).
More than that, stacks that compare people with the same role bring a different advantage by offering a direct comparison similar to the one done when someone is interviewed and we are looking into the salary we should propose to the candidate.
How do People Comparisons work on the Mindera People platform?
Let’s say our founders open a salary cycle. They share a message with the budget and the timelines for the cycle, and 50 people register a Salary Self-proposal.
In the past, our Reviewers Group (people involved in the review process) would reach out to 3–5 colleagues of each person and ask them:
If you had to compare yourself to the person asking for a salary review and another colleague, on a scale from 1 to 10, how would it look like?
Expecting an answer like:
I would be a 7, the person asking for a review would be a 4 and Peter (colleague) would be a 3.
It’s easy to understand how challenging this becomes when you’re looking to collect comparisons for 50 people, right?
There had to be a better way to do this, we just had to dig a little deeper and design a tool taking advantage of all the info we have on Mindera People — our internal tool with data about our people: roles, skills, experience, allocations (the projects we work for)…
And that’s how we created the People Comparisons tool!
For each of the 50 people that register a Salary Self-proposal, we run an algorithm that suggests the best 5 people to create a comparison stack and provide comments (if they wish to). The algorithm prioritizes people that work together on the same project for more than 90 days, have similar skills and experience.
Works like magic? The suggestions are always spot on? We wish! Just like us minders, the algorithm is going through a learning journey.
Every time we find a weak suggestion, we signal it and the algorithm learns not to give a similar suggestion in the future (we will come back to this in a moment).
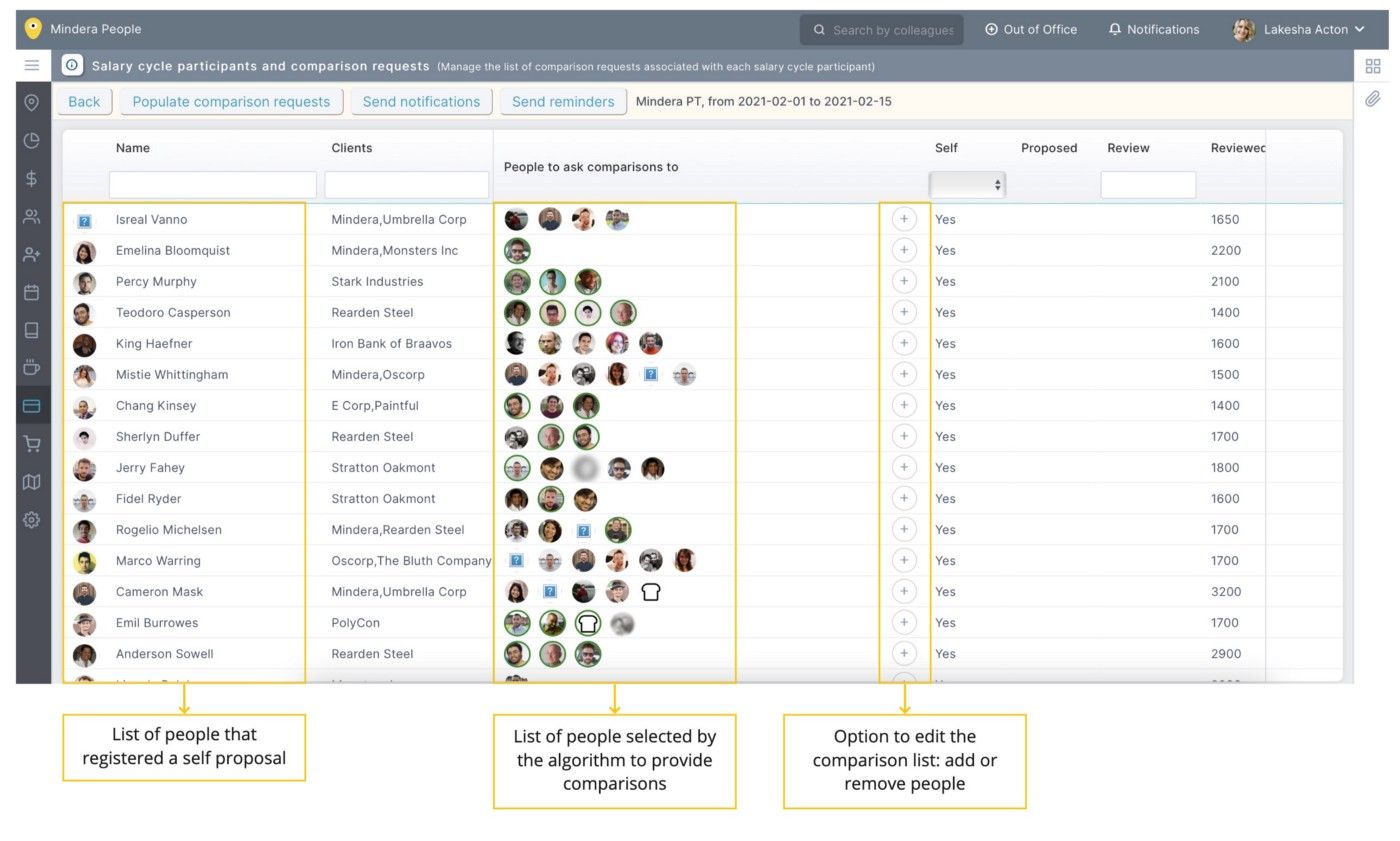
Based on the suggestions, we send a message to all selected people and invite them to create their comparison stacks. Each person can create several stacks (by team, role, experience…) and decide how many people to include in each of them. To help people do this exercise, we remind them of the purpose of the stacks:
The numbers in the stack represent a spectrum or a path — 1 is the starting point: where our development, experience, knowledge, impact on others starts; 10 is the most we have “travelled” so far in that spectrum. Example:
When comparing people, if John is at number 4 then placing people further in the path than John will be numbers 5–10, whilst placing people before John will be numbers 1–3
For this exercise, consider the person as a whole and everything they bring to Mindera: experience, knowledge, impact, interactions with others, and so on.
Remember about the algorithm weak suggestions we mentioned above? This is how we deal with them:
Imagine I’m Kate, and I received a request to compare João, Ana and Peter. I work with John and Ana so it’s easy to include them in a stack. Peter has the same role as me, but we never worked together. I can choose to discard this comparison request (not to include in any stack) or suggest another person that could provide feedback about Peter — we call this process “Make a referral”. This is what helps the algorithm to improve every cycle.
While the comparisons process is going on (during 2 weeks), our reviewers have a background view where they can confirm the number of comparisons given to each person — our goal is to collect at least 3–5 comparisons. If, for some reason, the reviewer finds a case with no comparisons, they can send extra requests to more colleagues.
In small teams, or in cases of people without peers with the same role in the team (PO, QA, Designers) our reviewers look for information in different groups such as clients that work with them.
What happens after we collect comparisons?
This is the moment when our reviewers start what we call sense check phase: analysing the stacks where each person was included and get a better picture of the appropriate salary spectrum.
Imagine I did a self proposal of 1500€ and my current salary is 1350€. My teammates included me in 3 stacks:
Stack 1 (made by Arjun): I’m on level 5, Bia (same role with a salary of 1550€) is on level 6 and Arjun (same role with a salary of 1250€) is on level 2
Stack 2 (made by Bia): I’m on level 6, Bia (same role with a salary of 1550€) is on level 6 and Matt (same role with a salary of 1950€) is in level 9
Stack 3 (made by Thomas): I’m on level 5, Bia (same role with a salary of 1550€) is on level 5 and Thomas (same role with a salary of 1000€) is on level 1
Stack 4 (made by Matt): I’m on level 3, Bia (same role with a salary of 1550€) is on level 3 and Matt (same role with a salary of 1950€) is in level 7
According to the stacks, my value is close to Bia and my self-proposal could be considered adequate. This is a simple one, and that’s not always the case. Sometimes the reviewers do a third or fourth round of comparison requests to help them make an informed decision.
Even though this model is not perfect, we are proud of finding a solution that involves everyone in the salary process: the reviewers group, the people asking for a salary review and the ones that work with them every day and witness their growth and provide comparison information.
After the sense check, everyone is notified about the result of their proposal — accepted, rejected, deferred for next cycle — and the reviewers share the cycle summary. It’s usually a message similar to this:
Hello everyone,
Update on current salary cycle. Cycle number 10!
Initial budget was X€. The total value after closing the process: Y€
- 111 people created a self-proposal in the platform Mindera People
- 105 were accepted. Below, value proposed or above.
- 5 were rejected
- 1 was deferred for next cycle
- 35 people were added to the cycle and reviewed.
- XYZ€ was the average of all increases.
- We did 14 salary sense check sessions in the last weeks
Thanks to everyone that contributed with the comparisons stacks, this is so vital to the process. Thanks so much
If you have any doubt on the process please talk with the salary group.
What’s the feedback?
In general, people were happy to jump into this adventure and see what it led us to. On the first cycle using this new tool, we got comparisons for 95% of the people participating in the cycle (this is something like 500 build stacks!).
Of course, we had some people that shared some concerns about the model, especially people in small teams that were afraid of not getting quality information from their peers — the case we mentioned above. We took time to hear all feedback and suggestions, and we keep improving our salary process.
What’s next?
You know us, we crave creativity and transparency! Some teams are exploring the possibility to use the comparisons tools for internal feedback sessions. Let’s see where we will end up. In a couple of years we will have a new story to share!
Share
Copy Page Url