Scaling GraphQL with Apollo Federation
GraphQL in Apollo’s solution and how to create create a simple API on this.

Image Credits: https://wehackthemoon.com/bios/margaret-hamilton
Apollo Federation allows the composition of multiple distributed GraphQL services into a unified single GraphQL API. In this blog post, we'll discover what Apollo Federation is, what it tries to solve, and how it allows a GraphQL API to scale by maintaining a single graph federated across multiple teams. We'll also create a simple API to get started on this specification.
Note: this blog post is part of Mindera's Women In Tech Month initiative. To everyone who paved the way for me to be able to write this today, I say thank you!
What problems does Apollo Federation solve?
The two-fold Apollo Federation definition: exposing a single endpoint and GraphQL schema to the clients while also giving teams flexibility and service isolation sheds some light on what use cases federation can help.
Implementing a single data graph on a monolithic GraphQL server becomes challenging to manage with an ever-growing data graph and its services. In addition, performance might degrade, making it increasingly difficult for the developers to collaborate as they commit changes to the same code base. Federation allows splitting the graph's implementation across multiple services (called subgraphs). Moving to a distributed GraphQL architecture allows each team to own a graph slice independently. At the same time, an extra layer sitting between the client and the services merges the schemas into a single schema that the clients can consume.
There is also the case where an organisation has multiple GraphQL micro-services but doesn't provide a unified interface to its clients, forcing them to communicate with the various services to fetch all the data they need. By unifying the graph with Apollo Federation, teams can independently own and develop their subgraphs. Clients can fetch data from all of those subgraphs from a single endpoint.
So do you need to break up your monolithic codebase because the complexity has risen drastically? Do you need different components in that monolithic to scale at different rates? Do the developers find it challenging to work in the codebase? Have you adopted a distributed microservice architecture, but do your clients need to query multiple endpoints?
Apollo Federation is a solution if you have a large project backed by a monolithic application and are experiencing the monolith pitfalls. Additionally, you can use it when your application is distributed across many services, and it would benefit from having a single entry point.
Why you should avoid Apollo Federation
If you don't relate to the issues above, likely, you don't have the problems that the federation tries to solve.
Adopting federation when your API is small adds complexity.
If you're not using GraphQL, be aware that the services have to be written as GraphQL services to use federation, which means an extra migration effort. The API consumers would also have to adopt GraphQL in that case.
The Apollo Federation architecture
The Apollo Federation architecture consists of the following:
- A set of subgraphs, each defining an independent schema, usually correspond to a different back-end service.
- A gateway that uses a supergraph schema (composed of all subgraph schemas) to execute GraphQL operations, distributing them across the subgraphs. Querying a gateway is the same process as querying any other GraphQL server.
Separation of concerns
Federation aims at code separation by concern, not by type, since often, the fields that compose a type are the responsibility of different services.
Let's consider we are building a GraphQL API called Cinema Lover, where people can query information about movies and directors.
A type-based separation consists of defining each type in its subgraph:

Consider the Director schema defined above, which has the Movies field. A list of movies should be declared and resolved in the Movies subgraph, not the Directors subgraph. Similarly, it wouldn't be correct to declare the Director field inside the Movies subgraph.
The Directors subgraph might not have access to the movies' datastore to resolve the Movies field of a Director. The same happens to the Movies subgraph, unable to access the directors' datastore to resolve the Directorfield.
A concern-based separation divides the types across the subgraphs when required:
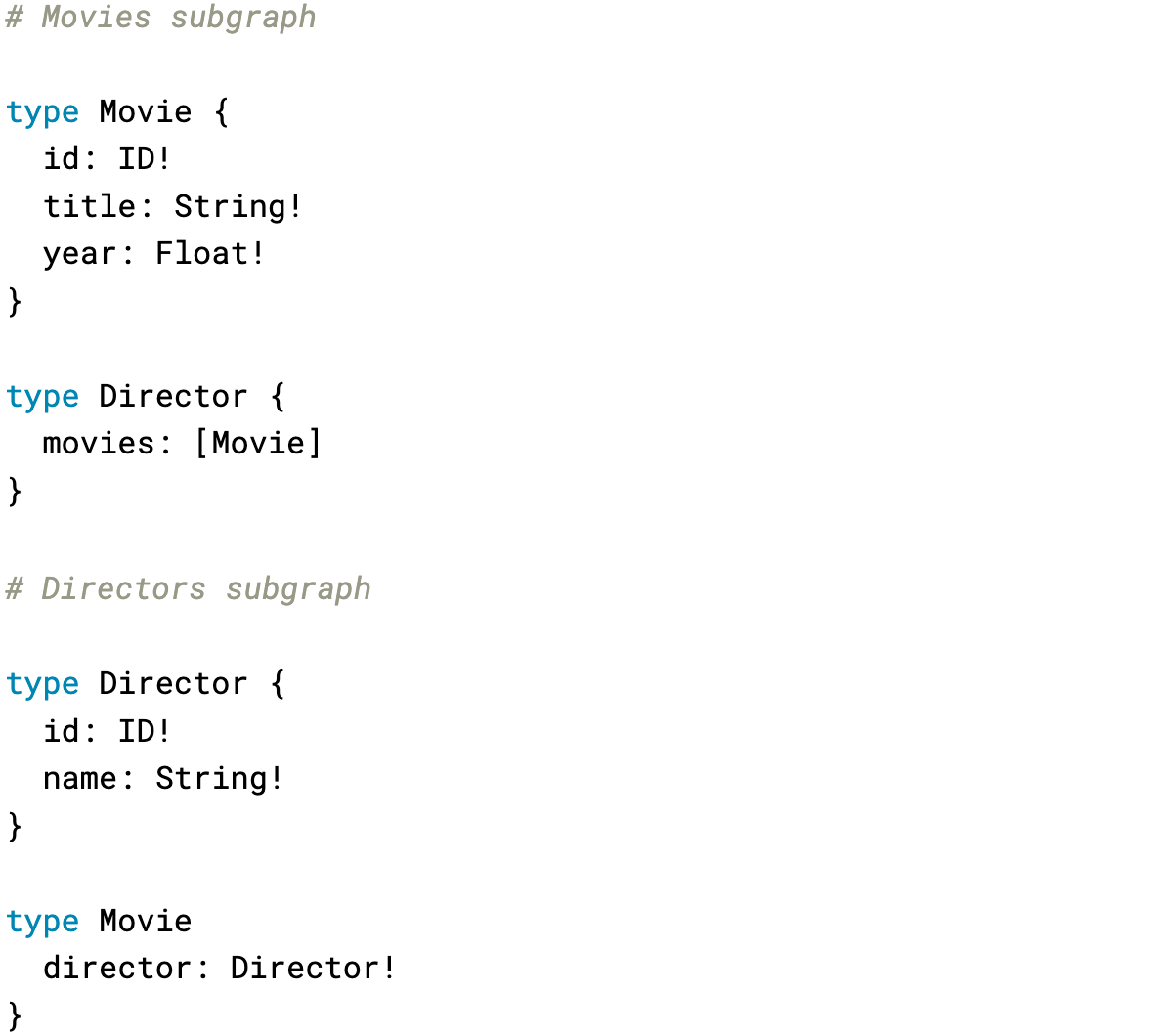
Segregating the fields of a type allows the subgraph that defines a field to know how to resolve it and have all the logic related to a type confined to a single subgraph.
The Cinema Lover API
Let's build our Cinema Lover Grapqhl API consisting of a gateway and two federated services: movies and directors. Each service will manage a portion of the overall schema.
We'll implement these services using Typescript, TypeGraphQL framework and the required Apollo libraries.
You can find the project here.
Directors service
We'll create a directors folder to implement all logic related to directors for this service.
First, we'll start by defining the Director schema. For the sake of this tutorial, our data source is a .ts file with a list of directors.

The @key directive in the Director schema defines it as an entity. An entity is a type you specify in one service and then reference and extend in other services.
The fields notation serves as a primary key to identifying individual directors' instances uniquely. In this case, the id property uniquely identifies a director.
Since we define an entity, the gateway will use a representation as an input to the service when another service is referencing the entity. A representation requires an explicit __typename definition and the values for the entity's primary key fields.
To resolve the Director entity, we add the following reference resolve:

The resolveDirectorReference method returns a director instance when provided with the primary key available in the reference parameter. Given our list of director objects, we find the director on that list given its id.
Let's also add a query resolve for clients to fetch the list of directors.

Now that we defined the schemas and the resolvers, it's time to build our federated schema and start our service.
We'll use a helper function to have federation working with the typegrapqhl framework and adapt the example provided by the library to the newer federation libraries supplied by Apollo.

We'll create the schema and the server for this service at our service entry point.
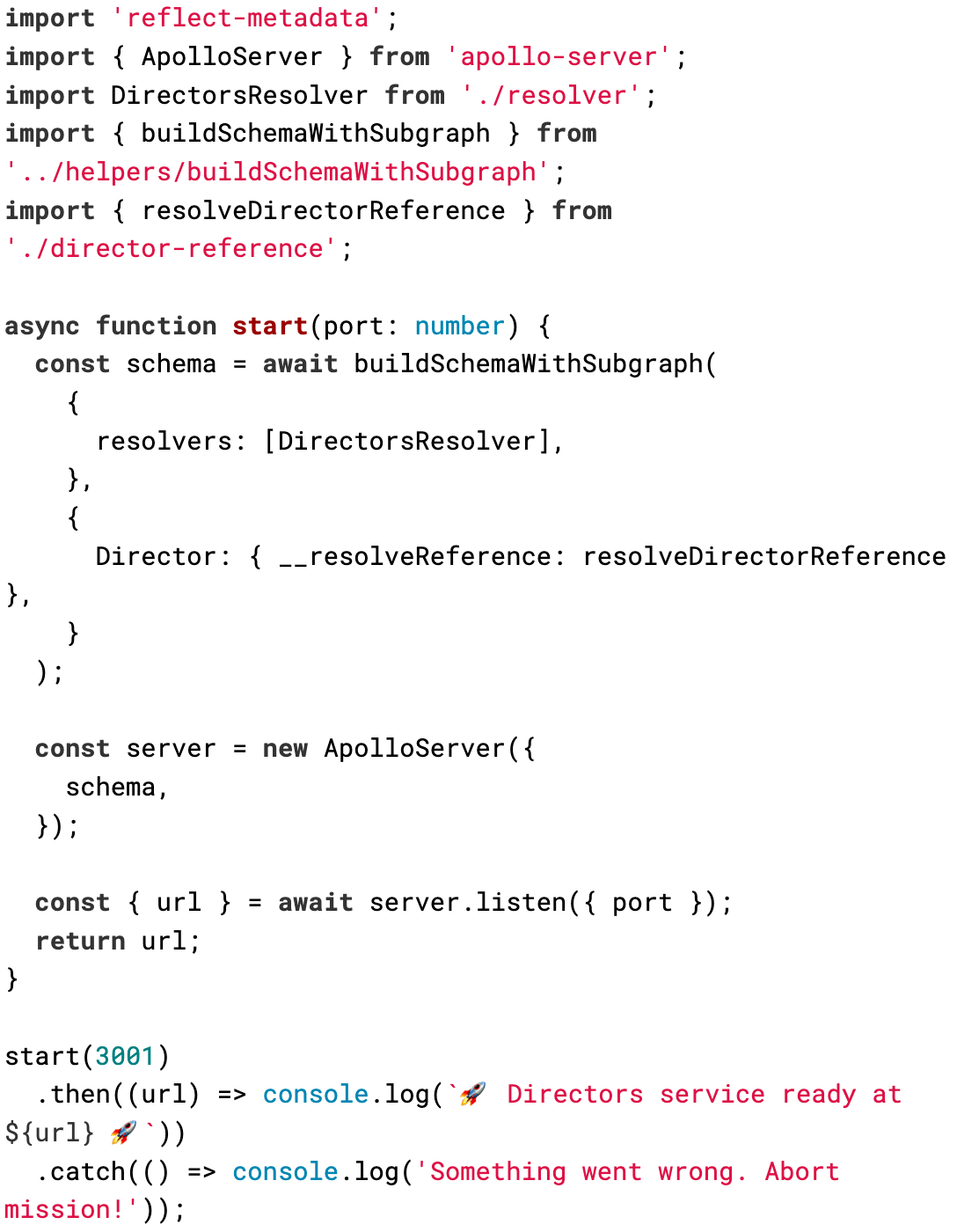
Once the server runs, if we head to the service URL, we'll see the default landing page for non-production environments.
If we access Apollo Sandbox, we can see the schema and query our directors' API.
Movies service
Let's create a movies folder to implement all logic related to movies.
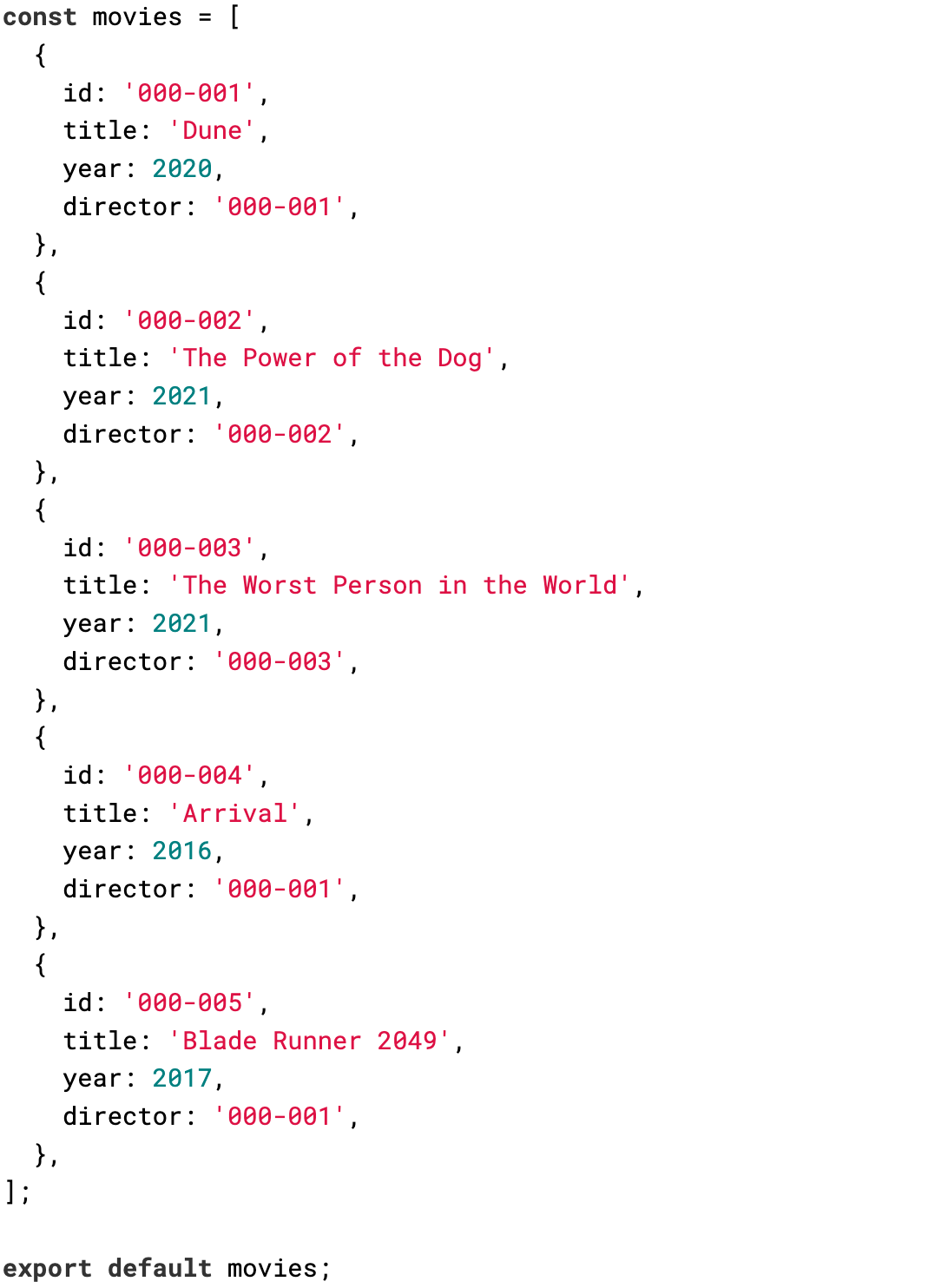
First, we'll start by defining the Movie schema. Here is our list of movies:
Then we define the Movie entity:
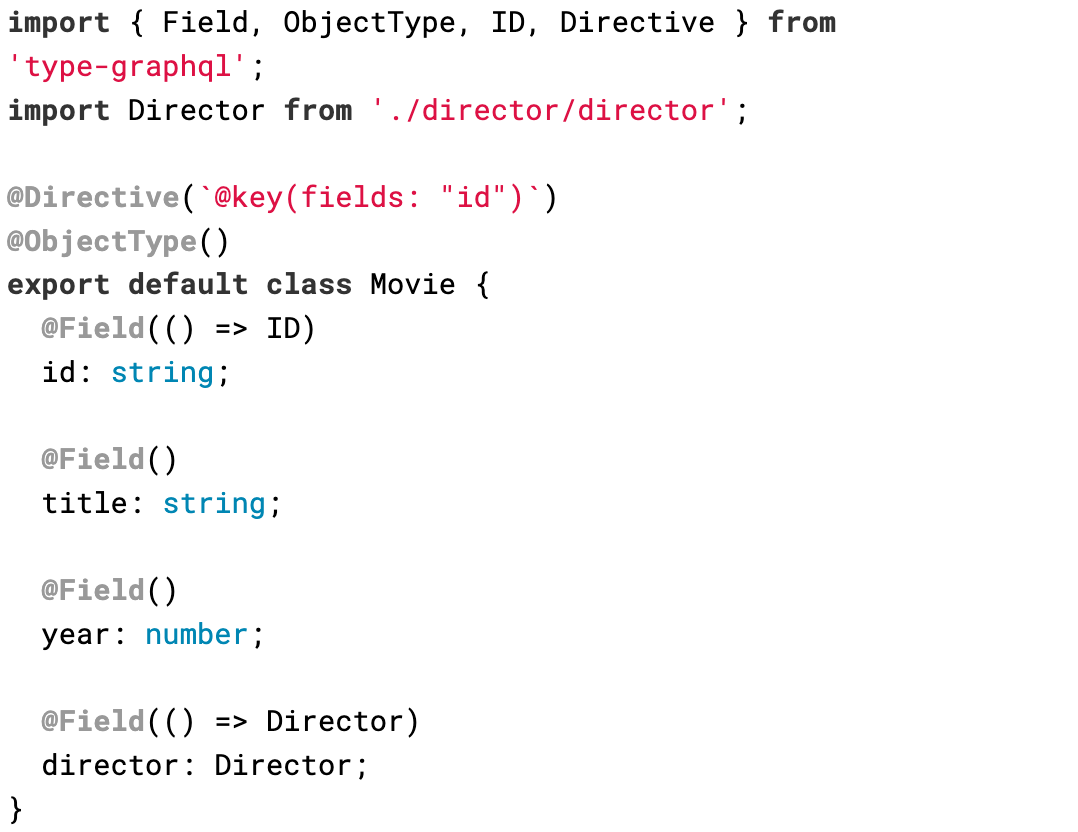
To resolve the Movie entity, we add the following reference resolver:

Given our list of movie objects, we find the movie on that list given its id.
Next, let's define our Director schema.

We extend the Director entity, defined in the directors service via the @extends directive.
The @key directive indicates that the Director entity uses the id field as its primary key. Therefore, we must add that field in our Director type definition and annotate it with the @external directive to indicate that the field originates in another subgraph.
Our movie service is responsible for managing movie information, so we'll extend our Director type by adding a list of movies. Our clients can query directors and get a list of movies they directed.
We'll add a movies field of type [Movie] to the schema and resolve this field via a field resolver.

Given our list of movie objects, we filter the ones only directed by the requested director.
We need a field resolver to populate our Director field in the Movie identity. To resolve this field from the entity we extended, we only need to return the representation for the director instance, which consists of the __typename and the id key field that identifies the director.
The gateway will be responsible for querying the appropriate service to fetch the director instance.
We'll also add a query resolver to return all movies.
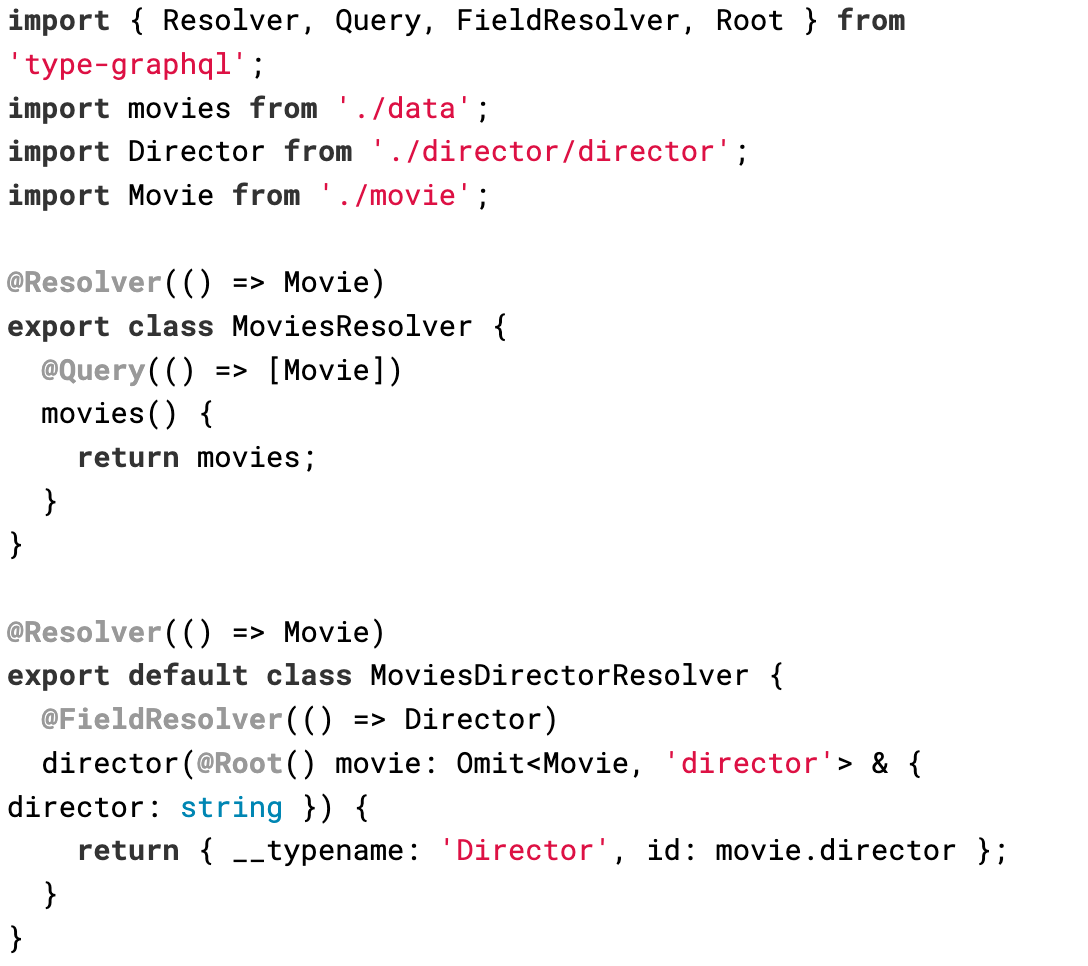
Finally, we can build the movies schema and start the service.

If we access Apollo Sandbox, we can see the schema and query our movies API.
We can query the list of movies and resolve the directors' movies since we extend this entity and have access to its primary key, thus allowing us to resolve a director's movies field.
However, if we try to query the director's name, the query will fail as that field is not defined in our extended Directorentity; hence, clients can't retrieve it via the movies API.
Note: there is a way to get more fields on an extended entity if necessary via the @provides directive.
Apollo gateway
Now that we have our services up and running let's create the gateway.
We'll use the Rover CLI for local schema composition.

Next, we create the configuration file with the subgraphs details for the rover to fetch and compose the schemas.
In our project root directory, let's create a file called supergraph-config.yaml and add our services URLs into it:
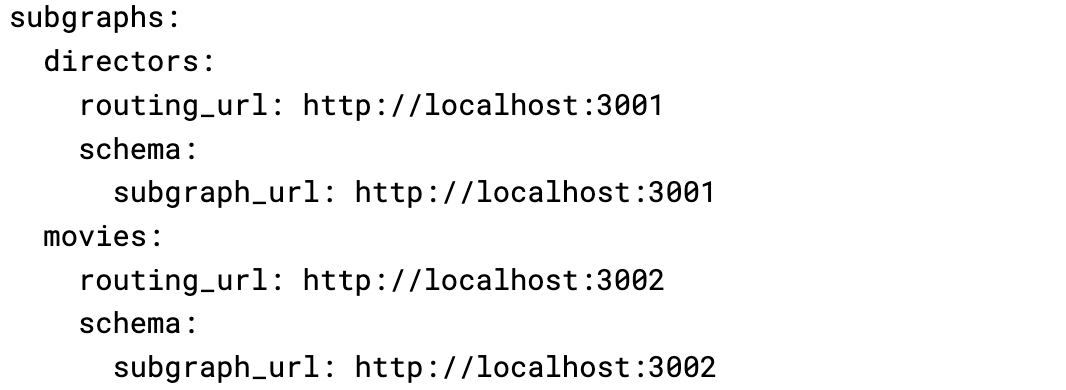
Since we use the same endpoint to receive graphql requests and serve the subgraph schema, the routing_url and schema.subgraph_url have the same value.
We run the following command from our project directory to compose the super graph: rover supergraph compose --config ./supergraph-config.yaml > supergraph.graphql
Our gateway will now use the generated supergraph file:

In our gateway, we're able to query both movies and directors.
We're able to query the same list of movies as in our movies service, but now via the gateway, we're also able to retrieve the director's name.
Additionally, we can query the same list of directors as in our directors' service, but now via the gateway, we can also retrieve the director's movies.
Managed federation
Rover CLI is suitable when developing locally, but Apollo provides a cloud-based service that's part of Apollo Studio called managed federation for other environments.
You can check an excellent talk about managed federation here.
What's next?
We covered the basics of Apollo Federation, but there is a lot to dig into: from the additional directives we can use when defining our entities to the functionalities available in Apollo Studio to compose, deploy, secure and monitor our federated graphs.
Check the official docs for more details about what's possible to do with the Apollo Federation.
Here is a list of resources I found helpful to get me started:
- https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-1-ae3557c187e2
- https://dev.to/mandiwise/your-first-federated-schema-with-apollo-3fhk
- https://medium.com/swlh/build-and-deploy-a-simple-apollo-graphql-federated-schema-using-aws-eks-kubernetes-pt-1-a6b79f7c8963
- https://www.apollographql.com/blog/community/what-i-learned-at-graphql-summit-f61d6fc6680a/
- https://www.apollographql.com/blog/announcement/announcing-managed-federation-265c9f0bc88e/
- https://www.youtube.com/watch?v=IOPiOr5fqYE
- https://aws.amazon.com/pt/blogs/mobile/federation-appsync-subgraph/
- https://principledgraphql.com/integrity